昨天一樣分步驟講解了 MHA 的運算,怕篇幅太長大腦過載,所以將程式放到今天。
複習一下 self-attention 程式步驟
開始前一樣先看一下大家名稱怎麼取
這裡一樣分步驟,大致上沒什麼變化,只是多了 split 這個 block,以及最後還要再過一個線性轉換,剩下比較需要思考的就是維度上的操作了
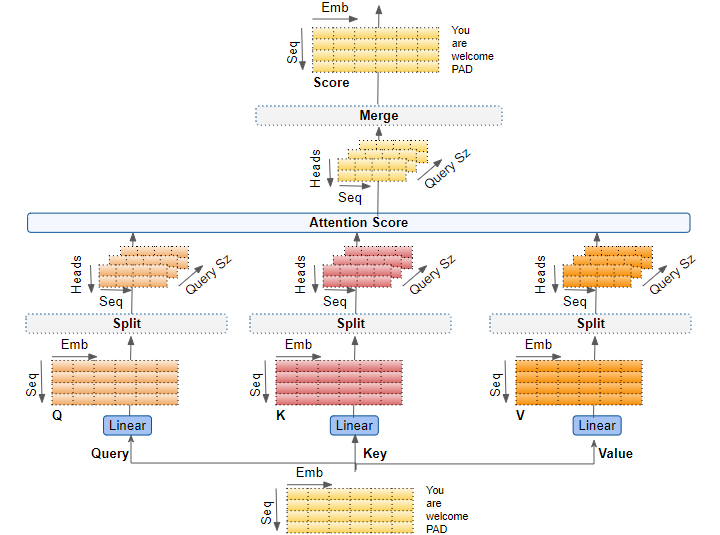
以下使用 linear_q, n_head, head_dim 等名稱
import torch
from torch import nn
import torch.nn.functional as F
# step 1
class MyMultiHeadAttention(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x: torch.Tensor):
'''
B: batch size
L: seq len
D: embedding dimension
x: (B, L, D) or (B, L, E) 簡寫每個都不太一樣
'''
return
import torch
from torch import nn
import torch.nn.functional as F
# step 2
class MyMultiHeadAttention(nn.Module):
def __init__(self, hidden_size, n_head):
super().__init__()
# 跟之前一樣
self.linear_q = nn.Linear(hidden_size, hidden_size)
self.linear_k = nn.Linear(hidden_size, hidden_size)
self.linear_v = nn.Linear(hidden_size, hidden_size)
# 多宣告及小地方不一樣
self.linear_o = nn.Linear(hidden_size, hidden_size)
self.head_dim = hidden_size // n_head
self.scaling = self.head_dim ** -0.5
def forward(self, x: torch.Tensor):
'''
B: batch size
L: seq len
D: embedding dimension
x: (B, L, D) or (B, L, E) 簡寫每個都不太一樣
'''
return
import torch
from torch import nn
import torch.nn.functional as F
# step 3
class MyMultiHeadAttention(nn.Module):
def __init__(self, hidden_size, n_head):
super().__init__()
# 跟之前一樣
self.linear_q = nn.Linear(hidden_size, hidden_size)
self.linear_k = nn.Linear(hidden_size, hidden_size)
self.linear_v = nn.Linear(hidden_size, hidden_size)
# 多宣告及小地方不一樣
self.linear_o = nn.Linear(hidden_size, hidden_size)
self.head_dim = hidden_size // n_head
self.scaling = self.head_dim ** -0.5
def forward(self, x: torch.Tensor):
'''
B: batch size
L: seq len
D: embedding dimension
x: (B, L, D) or (B, L, E) 簡寫每個都不太一樣
'''
B, L, D = x.shape
query = self.linear_q(x)
key = self.linear_k(x)
value = self.linear_v(x)
# (B, L, D) -> (B, L, n_head, head_dim) -> (B, n_head, L, head_dim)
query = query.view(B, L, -1, self.head_dim).transpose(1, 2)
key = key.view(B, L, -1, self.head_dim).transpose(1, 2)
value = value.view(B, L, -1, self.head_dim).transpose(1, 2)
# (B, n_head, L, head_dim) dot (B, n_head, head_dim, L) = (B, n_head, L, L)
attn_scores = torch.matmul(query, key.transpose(2, 3)) * self.scaling
attn_weights = F.softmax(aattn_scores, dim = -1)
# (B, n_head, L, L) dot (B, n_head, L, head_dim) = (B, n_head, L, head_dim)
attn_output = torch.matmul(attn_weights, value)
# 可以自行選用其中一個 -> 怎麼來的怎麼回去
# (B, n_head, L, head_dim) -> (B, L, n_head, head_dim) -> (B, L, D)
attn_output = attn_output.transpose(1, 2).contiguous().view(B, L, -1)
# attn_output = attn_output.transpose(1, 2).reshape(B, L, -1)
attn_output = self.linear_o(attn_output)
return attn_output
當初我在學的時候總覺得維度操作有點麻煩,但看著圖實際動筆在紙上寫一次,後來漸漸就熟悉了,雖然上面的 code 離實際應用還差一點點,不過已經可以試試看去看人家大公司寫的 code (transformers, Nemo, …),或許你會像我當初一樣忽然讀懂了。 今天就先到這裡囉~~
如果覺得對你有幫助,歡迎動動小手點個讚~


 iThome鐵人賽
iThome鐵人賽